안녕하세요! 데코입니다!
오늘 공부하는 빅데이터 분석 글 손글씨
고급 분석 기술 섹션에서. “앙상블 분석“일을 정리하려고 해요!
(출처: 이기적인 빅데이터 분석에 관한 글 – 시험집 2023)

1. 앙상블의 중요성
– 앙상블 기법은 주어진 데이터로부터 여러 학습 모델을 생성한 후 학습 모델을 결합하여 최종 모델을 생성하는 개념
1) 약한 학습자(약한 분류기, 약한 학습자)
– 높은 성공 확률, 무작위 선택 없음. 즉, 오류율이 일정 수준 이하(50% 이하)인 학습 규칙(상대적으로 부정확한 규칙, 분류기)
스팸 메일 처리 기술이 발달했다고 가정하면 스팸을 판단하는 기준은 여러 가지가 있다.
스팸이 예/아니오 기준으로만 판단된다고 가정해 봅시다.전)
제목에 광고 스팸(예) 본문에 보험/대출이 있는 경우 스팸(예) 보낸 사람이 내 주소록에 있는 경우 스팸 없음(아니요) 위의 예에서와 같이 모든 이메일에 적용할 수 있을 만큼 강력한 특정 기준이 있지만 그렇지 않은 기준도 있습니다.
이와 같이 결과 도출에 부분적인 실패 가능성을 포함하는 다양한 학습 기준을 “약한 학습자”라고 합니다.
2) 강한 학습자(약한 분류기, 강한 학습자)
– 약한 학습자가 생성한 강력한 학습 규칙(상대적으로 정확한 규칙, 분류기)
2. 앙상블 분석의 이해
– 앙상블 분석은 동일한 학습 알고리즘을 사용할 때 개별 학습자 성능보다 더 나은 분석 성능을 나타냄
– 앙상블 기법은 다양한 약한 학습자를 통해 강한 학습자를 만들어가는 과정이다.
삼. 앙상블 분석의 유형
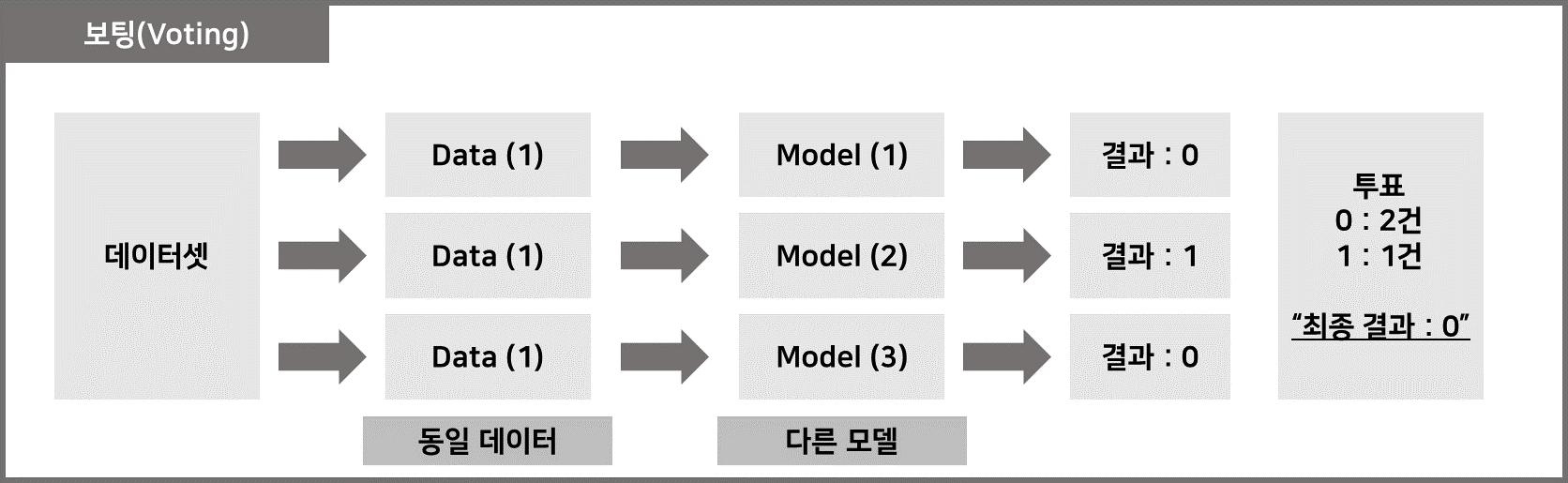
1) 투표
– 문자 그대로 투표로 결정하는 방법입니다.
– Voting은 투표 방식이라는 점에서 bagging과 비슷하지만 사용법에 차이가 있습니다.
# 투표와 배깅의 차이점
– 투표는 여러 학습 모델의 조합을 사용합니다.
– Bagging은 동일한 알고리즘 내에서 다른 샘플 데이터 조합을 사용합니다.
– 즉, 투표는 서로 다른 알고리즘(모델)에서 도출된 결과에 대한 최종 투표 방식을 통해 최종 결과를 선택합니다.
– 하드 투표투표를 통해 결과의 최종 가치를 결정하는 방법
– 부드러운 튜닝최종 결과의 확률 값을 모두 합산하여 각 최종 결과의 확률을 계산한 후 최종 점수를 도출하는 방법입니다.
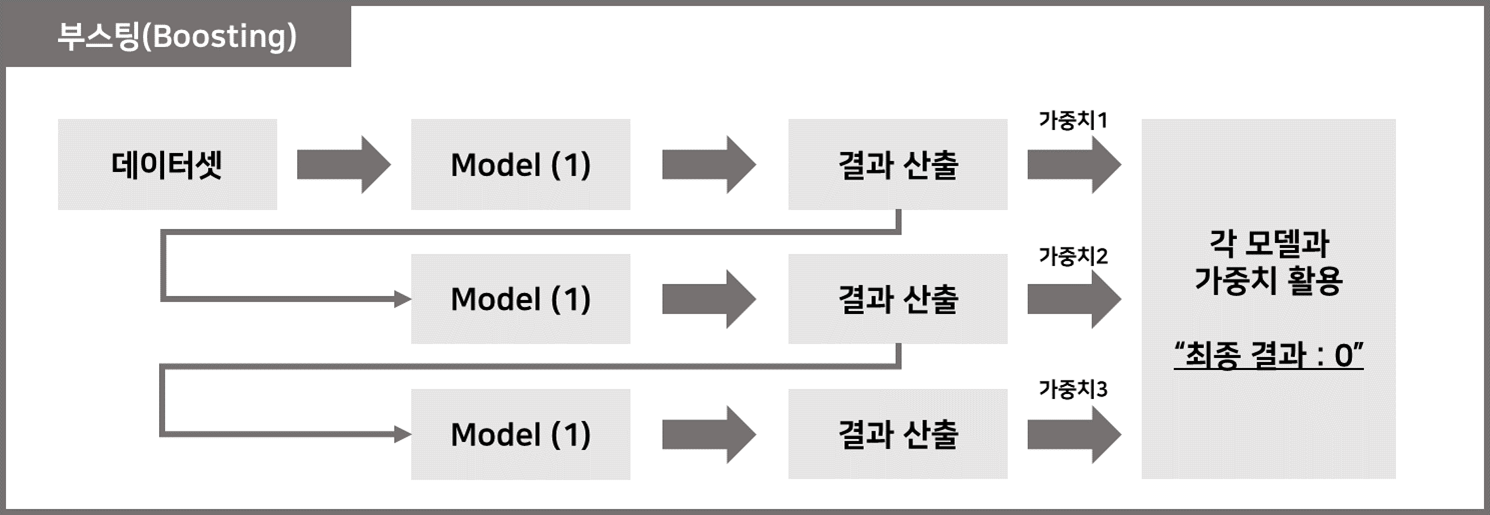
2) 부스트
– 가중치를 사용하여 순차 약한 학습자를 생성하여 강력한 학습자를 만드는 방법
– 순차적 학습을 수행하고 가중치를 부여하여 오류를 보완
– 순차적 특성으로 인해 병렬 처리가 어렵고 다른 앙상블보다 학습 시간이 오래 걸림(불리)
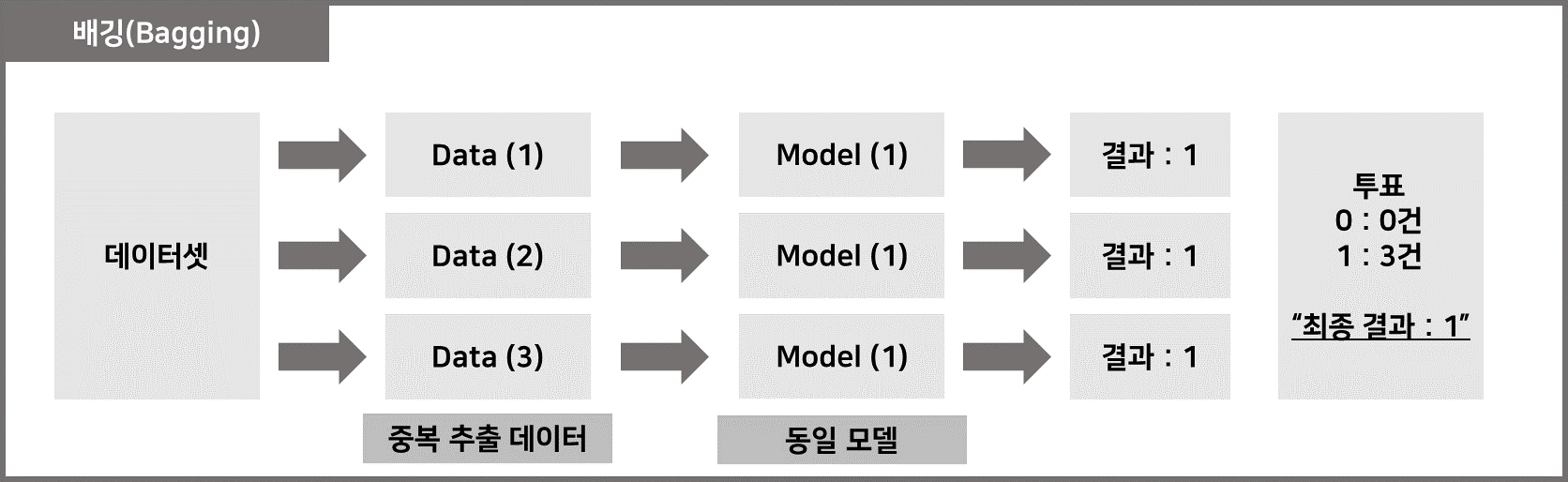
3) 배깅(부트스트랩 집계)
– 여러 번 샘플링(부트스트랩)하고 출력을 집계하여 각 모델을 교육하는 방법
# 새깅 사용법
1. 데이터에서 부트스트랩 진행(재구성을 통한 무작위 샘플링)
2. 부트스트랩 데이터를 사용한 모델 교육
3. 학습된 모델의 결과를 집계하여 최종 결과값 산출
– 범주형 데이터는 투표 후 결과 집계, 연속 데이터는 평균 집계
– 선택한다는 것의 의미
예) 6개의 결정 트리 모델(카테고리 데이터 – 투표 수)
4트리 모델: 예측
2트리 모델: B-예측
= 투표를 통해 더 많은 예측을 가진 A의 최종 선택
예) 6개의 의사결정 트리 모델(연속 데이터 – 평균 집계)
2가지 트리 모델: 4가지 예측
2가지 트리 모델: 6가지 예측
2개의 트리 모델: 8개의 예측
= 평균적으로 마지막 6개 선택
– Bagging은 간단하지만 효과적인 방법입니다. 대표적인 모델은 “랜덤포레스트”
오늘 저는 Big Data Analyst 필기 시험을 준비하고 있습니다.
앙상블 분석 내용을 정리해보았습니다!
앙상블 분석, 과거에 데이터 분석에 지원한 적이 있지만,
나는 “처짐과 부스팅의 차이점을 설명하십시오! “라는 질문을 받았습니다!
제 생각에는 필기시험 앙상블 테크닉에서
– 배깅/부스팅/보팅의 개념 (하드 보팅, 소프트 보팅)
– 패킹시 부트스트랩은 “복구된 랜덤샘플(중복가능)”
이 부분에서 문제가 생길 것 같아요!
설명하기 어려운 부분이나 잘 이해되지 않는 부분
질문이 있으시면
댓글을 남겨주세요!
여러분의 궁금증을 빠르게 해결해드리겠습니다!
좋아요와 댓글은 큰 힘이 됩니다!
오늘도 이 글을 읽어주셔서 감사합니다! 🙂
